之前公司在公司第一次用 Netty 做游戏服务器,在网上找的 Demo,就把游戏服务器做起来了,但是一直也没有管去优化,最近在开始总结和回归的时候,会思考一些问题?
- Netty 为什么要用 ByteBuf 呢?NIO 不是已经有了 ByteBuffer 了吗?
- 除了 Unpooled.buffer() 还有没有别的方法返回 ByteBuf 呢?
- 好多对象的数据长度是固定的,在写数据中,能不能申请固定长度的 ByteBuf 呢?
- 使用了这么多 ByteBuf,系统会不会有大量的时间在拷贝 byte[] 数组呢?
- ByteBuf 如何才能高效的使用呢?
1. ByteBuf 功能说明
往往在做 IO(网络 IO, 文件IO ) 操作时, 会用到缓冲区。缓冲区的作用就是,当有数据的时候,不会立即写入,而是先放到一个地方暂存,等数据存到一定的量过后,再做写入操作。
在 NIO 中,有提供一个 ByteBuffer 操作类,为什么 Netty 还需要一个 ByteBuf 呢?这个就要说到 ByteBuffer 的缺点了:
- 长度固定,一旦分配完成,容量不能动态扩展和收缩。对象小了容易浪费,一旦需要的长度大于分配的长度,又会引发越界异常。
- ByteBuffer 只有一个标识位置的指针 position,导致同时操作读写的时候会操作同一个 position,增加操作的复杂度,而且容易出错。
基于上面的原因,Netty 自己提供了一个自己的实现 ByteBuf。
1.1. ByteBuf 的工作原理
实现的方法可以用两种:
- 参考 NIO 的 ByteBuffer 实现,自己实现,解决已有的问题。
- 基于 ByteBuffer,使用 Facade 模式对其进行包装,降低实现成本。
ByteBuf 提供了两个位置指针,一个 readerIndex(读操作),一个 writerIndex(写操作)。
一开始的时候,readerIndex = writerIndex = 0。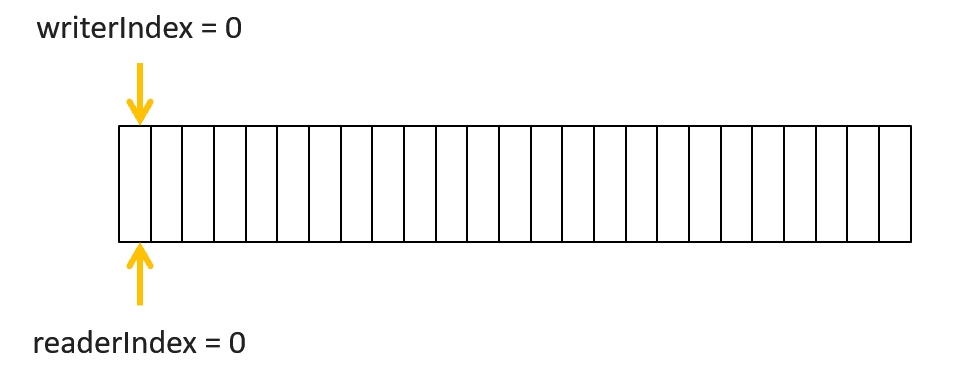
当操作写的时候,移动 writerIndex,readerIndex 不变。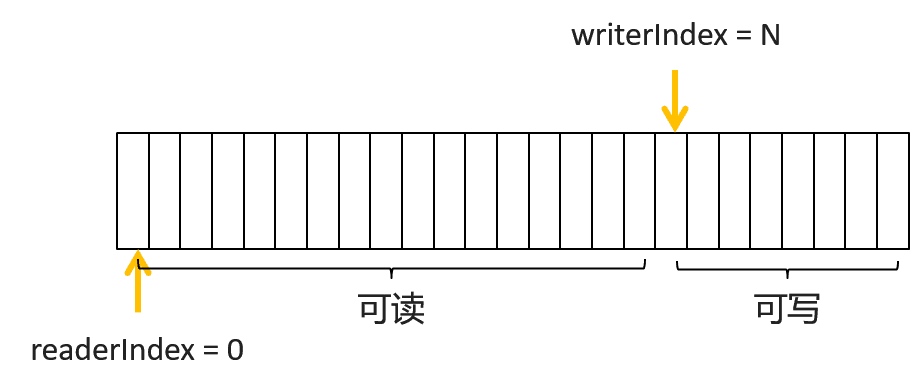
当操作读的时候,移动 readerIndex 指针,但是要保证 0 < readerIndex <= writerIndex. 其中 0 到 readerIndex 中的数据已经无用了,可以调用 discardReadBytes 方法。
这样,因为读写的指针分离开了,就不会出现使用 ByteBuffer 时,常常忘记 flip() 操作而导致读写错误了。
ByteBuf 在 write 数据时,会自动的检查剩余容量是否小于当前需要的容器,如果小于,会自动扩容。
由于 NIO 中的 Channel 读写的参数都是 ByteBuffer,所以 ByteBuf 需要能很方便的转换为 ByteBuffer. 正是因为这样,所以 ByteBuf 内部实现是采用第二种方式,聚合了一个 ByteBuffer.
1.1.1. discardReadBytes 方法
当 ByteBuf 调用了 read 方法过后,那么 0 到 readerIndex 之前的数据就没有用了,可以是所以 discardReadBytes 方法重用这部分空间,以节约内存。这个往往在私有协议栈消息解码的时候非常有用,因为 TCP 底层可能念包,几百个整包消息被 TCP 粘包后作为一个整包发送。
但是,注意,discardReadBytes 的实现方式是把 当前 readerIndex 到 writerIndex 之前的数据复制拷贝到 index = 0 的位置,如图:
1 | * BEFORE discardReadBytes() |
这样会发生字节数组的复制,所以,频繁调用的话会导致性能下降,所以调用的时候需要确定是否需要调用。
1.1.2. clear 方法
该方法不会将 ByteBuf 中的数据都填充为 0, 仅仅只是设置 readerIndex=writerIndex=0。
1.1.3. Mark/Reset
Mark 备份指针的位置,Reset 重制 指针的位置:
- markReaderIndex():将当前的readerIndex备份到markedReaderIndex中;
- resetReaderIndex():将当前的readerIndex重置为markedReaderIndex的值;
- markWriterIndex() :将当前的writerIndex备份到markedWriterIndex中;
- resetWriterIndex():将当前的writerIndex重置为markedWriterIndex的值;
1.1.4. Derived buffers
- duplicate,返回当前 ByteBuf 的复制对象,复制后返回的 ByteBuf 和当前操作的 ByteBuf 共享缓冲区中的内容,只是自己有自己的读写索引。修改复制后的 ByteBuf,会同时修改被复制的 ByteBuf.
- copy,返回新的 ByteBuf 对象,内容和索引都是独立的。
1.1.5. 转换成标准的 ByteBuffer
通过 nioBuffer()方法返回一个 ByteBuffer 对象,两者共享同一缓冲区内容。对 ByteBuffer 的操作不会修改原 ByteBuf 的读写索引。需要指出的是,返回后的 ByteBuffer 无法感知原 ByteBuf 的动态扩展操作。
1.2. ByteBuf 源码
1.2.1. ByteBuf 的类结构图
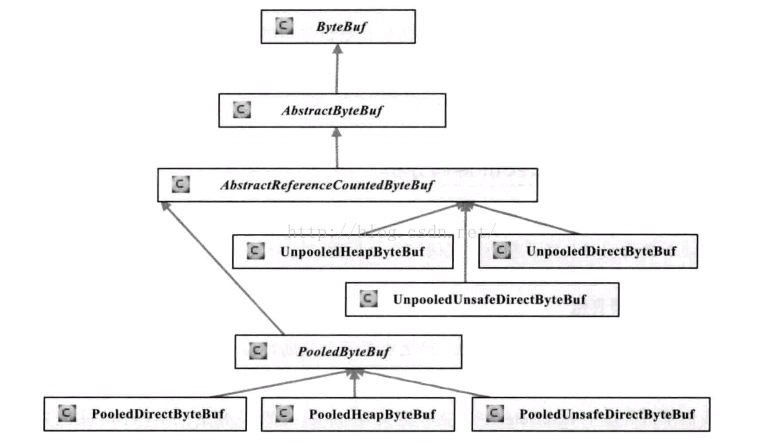
1.2.1.1. 按照 Heap/Direct 分类:
- Heap 在 JVM 堆分配内存,特点是内存的分配和回收速度快,可以被 JVM 自动回收;缺点就是如果进行 Socket 的 I/O 读写,需要额外做一次内存复制,将堆内存对应的缓冲区复制到 Channel 内核中,性能有一定程度的下降。
- Direct 在非堆内存,在堆外分配内存,分配和回收速度慢了一些,但是在写入 Socket Channel 中,没有复制,所以速度比堆内存快。
正因为这样,所以最佳实践是在 I/O 通信线程的读写使用堆 DirectByteBuf 会好一些,后端业务消息的编解码模块使用 HeapByteBuf,这样组合可以达到性能最优
1.2.1.2. 按照 Pooled/Unpooled 分类:
- Unpooled 每次分配内存申请新内存,频繁进行大块内存的分配和回收,对性能会造成一定的影响。
- Pooled 预先分配好一整块内存,分配的时候用一定算法从一整块内存取出一块连续内存,可以重用 ByteBuf,提高内存利用效率,减少 GC 次数。Netty 的实现叫做 PoolArena。
PoolArena:Arena本身是指一块连续区域,Netty 的 PoolArena 由多个Chunk 组成,每个 Chunk 由多个 Page 组成,并形成一个多层的二叉树,最底层是一个 Page,使用的时候采用深度优先的遍历,选择在合适的层进行分配。
无论是Chunk和Page,都通过状态位来标识内存是否可用。
1.2.1.3. 按照非 Unsafe / Unsafe 分类:
- 非 Unsafe [调用 JDK 的 API 进行读写]
- Unsafe [通过 JDK 的 Unsafe 对象基于物理内存地址进行数据读写]
1.2.2. ByteBuf 动态扩容的规则
首先设置门限阀值为 4MB. 当需要的新容量正好等于 4MB,使用 4MB 为新的缓冲区容量。如果申请的内存空间大于 4MB,不能采用倍增的方式扩展内存(防止内存膨胀和浪费),而采用每次步进 4MB 的方式进行内存扩张。扩张的时候,需要和最大内存(maxCapacity)进行比较,如果大于缓冲区的最大长度,则使用 maxCapacity 作为扩容后的缓冲区容量。
如果扩容后的新容量小于 4MB,则以 64 为技术进行倍增,直到倍增后的容量大于或等于需要的容量值。
其实就是保证在每次申请内存的时候,尽量多给一点内存,防止多次申请,造成扩容时内存多次复制,导致性能下降。但是,又不能多太多,防止内存的浪费。所以,在 4MB 以下才有倍增,在 4MB 以上采用步进的方式。
1.2.3. retain/release
每一个新分配的ByteBuf的引用计数值为1,每对这个ByteBuf对象增加一个引用,需要调用ByteBuf.retain()方法,而每减少一个引用,需要调用ByteBuf.release()方法。当这个ByteBuf对象的引用计数值为0时,表示此对象可回收。(涉及到 CAS(Compare And Swap)。

