1. tcp backlog 参数
- tcp 在三次握手的时候:
- client 会发送一个 SYN 到 server。此时,客户端的 tcp 状态会变成 SYN_SEND,server 收到 SYN包后,将连接状态修改为 SYN——RCVD,维护一个 half open sync queue(半连接)队列,将当前连接加入到半连接队列。半连接的长度为 max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog) 。
- server 端给客户端回应一个 SYN_ACK 的包给 client。client 收到后,会将连接修改为ESTABLISHED,然后发送 ACK 到 server。
- server 收到 client 的 ACK 过后,将连接的状态修改为 ESTABLISHED,并把请求从 sync queue 半连接队列放到 accept queue,长度为min(backlog, somaxconn)。
- linux 在内核中维护了两个队列:sync queue 和 accept queue.
- backlog 和 somaxconn 两个参数,确定了 accept queue 的长度。
- 通过 ss -ln 命令查看 系统每个端口配置的 send-q 的长度。
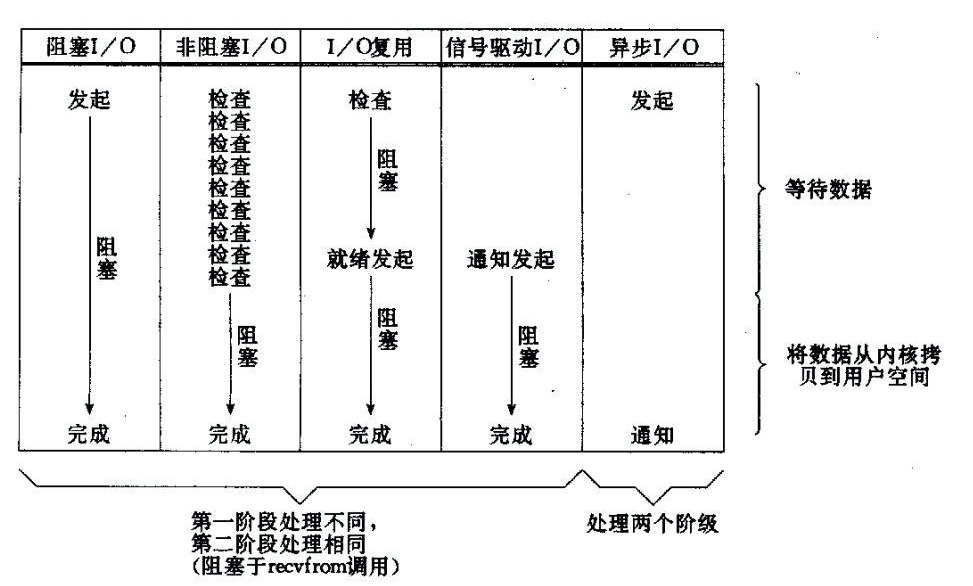
2. IO 五种模型
讨论 IO 时关键的两个对象:
1. 调用 IO 的 process 或者 thread
2. 系统 kernerl
2.1. BIO
- 用户进程发起调用,kernel 准备数据,如果数据不完整,需要等待,那么 kernel 会一直等到数据完成,然后 kernel 将数据拷贝到用户内存,然后 kernel 返回结果
- 用户进程此时解除 blocking 的状态。
- 用户进程在等待,kernel 也在等待。所以 BIO 的情况下,两个阶段都被 block 了。
2.2. NIO
- 用户发起调用,如果 kernel 没有准备好,kernel 返回给 用户一个 error。此时用户不需要等待,而是马上获得了一个结果。当用户线程得到一个 error 时,会再次向 kernel 发起一个 read 操作。当 kernel 准备好了数据,并且又再次收到了用户线程的 read 操作,kernel 马上就将数据拷贝到用户内存,然后返回。
- 此时,用户线程,需要不断的询问 kernel,是否有准备好数据。
2.3. IO 复用(事件驱动 IO)
- select/epoll 的好处就在于单个 process 或者线程,可以同时处理多个 socket。
- 当用户进程执行 select,用户线程阻塞block,同时,kernel 会监听所有当前 select 负责的 socket,当任何一个 socket 中的数据准备好,select 就会返回,这个时候用户再执行 read 操作,将数据从 kernel 拷贝到用户内存。
- IO 复用和 BIO 类似,事实上,更差,因为要执行两次系统调用,一次是 select,一次 read,而 BIO 只执行了一次 read。但是select的好处在于,一个 select可以监听多个 socket(所以,如果连接数不高,select/epoll 的 web server 性能,不一定比 multi-thread + BIO 性能更好。select 的优点不是在于处理单个连接更快,而是能处理多个连接)。
- 对于 IO 复用,其实整个用户的 process 是阻塞的,阻塞的是 select 操作,而不是 socket IO。
- select, poll, epoll 的区别:
- select的几大缺点:
- 每次调用 select,都需要把 fd 集合从用户态,拷贝到内核态,当 fd 很多时,开销很大。
- 然后,select 都需要在内存遍历所有传递进来的 fd,在 fd 很多时,开销很大。
- select 支持的 fd 数量太小了,默认是 1024,可以修改到 65535.
- select 和 poll 的区别,描述 fd 集合的结构不一样,poll 使用 pollfd 结构,而 select 是fd_set 结构
- select 在 fd 很大量时,性能问题,出现了 epoll
- fd 不受限制,只受操作系统的最大文件句柄数限制。
- select 和 poll每次都会遍历所有的 fd,而 epoll 对每个 fd 上添加 callback 回调函数,当 fd 活跃时,会把自己加入到一个 活跃队列里。
- mmap,select,poll 需要将用户内存中的 fd 复制到内核中,而 epoll 使用 mmap 让内核和用户空间使用同一块内存。
- select的几大缺点:
2.4. 信号驱动 IO(不常用)
2.5. AIO(用得少)
- 用户线程发起 read 操作,kernel 收到请求后,马上返回,不会对用户线程产生任何的 block. 然后 kernel 在准备完成数据后,并且将数据拷贝到用户内存后,kernel 会发一个信号告诉用户线程,它 read 完成了。
- AIO 和 NIO 的区别:在 Server 端的体现为 Reactor 和 Proactor 的区别,NIO 是kernel 通知调用线程,数据准备好了,你可以来读了;而 AIO 是 kernel 通知调用线程,你要的数据,我已经读完,给你放到用户内存了。
3. 阻塞,非阻塞,同步, 异步,到底是什么?
阻塞和非阻塞的区别,就是表示发起系统调用的线程是否会被 block。阻塞时,用户线程被 block,非阻塞时,系统 kernel 在数据没有准备好时,马上给用户线程一个结果,否则,用户线程直接读取数据到用户内存(此时用户主线程是阻塞的)。
同步 IO 和 异步 IO 的区别是指:同步 IO 在做 IO 操作时,用户线程是否会被阻塞。
BIO,NIO,IO 复用都属于同步IO,NIO 在得知 kernel 中的数据就绪后,开始读取数据时,这个时候的 IO 操作是阻塞的。只有 AIO 是异步 IO 操作。
举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
4. Reactor 和 Proactor 到底是什么?
- Reactor 和 Proactor 是一种多用在服务端的设计模式。
- Reactor 模式是指,有一个不断的等待或者循环的单独的线程,接受所有的 handler (创建连接,接收数据包,写数据包)的注册,然后向操作系统查询IO 是否就绪,如果就绪则调用响应的 handler 中的方法,执行请求,这个线程的角色就是 Reactor. —— Don’t call us, we’ll call you.
- 在 Reactor 模式中,操作系统只负责通知 IO 就绪,具体的 IO 操作,读写,还是需要在自己的业务线程 handler 中去做。而 Proactor 则更近一步,操作系统直接将 IO 操作执行完成,例如读取,直接将数据读取到内存 buffer 中,而 handler 只负责自己的逻辑,真正做到了 IO 与程序处理异步执行。所以,我们说 Reactor 一般是同步 IO,Proactor 是异步 IO.


v1.4.16